第三章 文字
 知识点八:汉字的整理和标准化
知识点八:汉字的整理和标准化
一、汉字改革问题
文字改革包括文字制度上的变革和文字内部的简化、整理两方面的内容。
汉字在汉民族文化史、交流史上都有过不可磨灭的功绩。直到现在,汉字仍是汉民族通用的文字。但是,汉字数量浩繁,形体复杂,给人们的学习和使用带来很大困难,不能很好地适应科学技术现代化的需要,应该进行改革。
新中国成立后,国家建立了主管文字改革的专门机构——中国文字改革委员会(简称“文改会”);20世纪50年代,制订了积极而稳步地进行文字改革的方针,确定了简化汉字、推广普通话、制定和推行《汉语拼音方案》三大任务。
改革开放以来,我国各项方针政策都得到了符合客观实际的调整。1985年国务院决定将原中国文字改革委员会改名为国家语言文字工作委员会,重新明确了它的工作范围和职责。1986年1月,中央批准国家教委和国家语委在北京联合召开全国语言文字工作会议,制定了新时期的语言工作方针:研究和整理现行汉字,制定各项有关标准,研究汉字信息处理问题,促进汉字的规范化、标准化等。这就是当前汉字工作的主要任务。
二、汉字的整理
汉字的整理包括简化笔画、精简字数和其他方面的整理。汉字整理的最新成果是2013年6月国务院公布的《通用规范汉字表》。
(一)简化汉字
1956年1月28日,国务院公布了《简化汉字方案》,方案中的简化字分四批推行。经过8年多的实践,到1964年5月,总结、归纳成《简化字总表》出版。《简化字总表》分三个字表,第一表是350个不作简化偏旁用的简化字,第二表是132个可作简化偏旁用的简化字和14个简化偏旁,第三表是应用第二表所列简化字和简化偏旁类推出来的1754个简化字。1986年又对其中个别字作了调整,重新公布了《简化字总表》,调整后的《简化字总表》共有简化字2235个。1988年《现代汉语通用字表》又收入了《简化字总表》之外的120个简化字,全部是类推简化字。这样,大众学习和使用汉字更方便了。2013年《通用规范汉字表》又收录了《简化字总表》和《现代汉语通用字表》之外的220多个类推简化字,在这个字表中,简化字总数为2546个。
汉字简化方法是千百年来特别是近百年来群众创造的,主要包括以下几种。
(1)类推简化
简化一个繁体字或繁体字的部件,可以类推简化一系列繁体字。类推简化可以使一些简化字和繁体字之间有对应规律。这种简化方法是最有效的方法。利用《简化字总表》第二表132个简化字和14个简化偏旁合计简化了第三表的简化字1753个,占简化字总数的78.4%。例如

(2)同音或异音代替
在意义不混淆的条件下,用形体简单的同音或异音字代替繁体字,既减少了字数,又突出了表音的特点。例如:

(3)草书楷化
草书笔画简单,多是一笔书,打破了楷书的形体和结构,但笔画不清晰。把群众比较熟悉的草书字的笔形改用楷书的写法,就可以达到减少笔画的要求。例如:
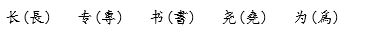
(4)换用简单的符号
用一个笔画很简单的符号代替繁体字中特别繁难的部分。例如:

(5)保留特征或轮廓
把繁体字中繁难的部分删去,只留下表示这个字的特征或轮廓的部分。用这种办法简化的字称为特征字、轮廓字。例如:

(6)构成新的形声字或会意字

汉字简化取得了明显的效果。首先是减少了笔画数目。《通用规范汉字表》2546个简化字平均每字10.5画,被简化的2574个繁体字平均每字16.1画,平均每字减少5.6画。其次,减少了通用汉字的字数。用同音或异音代替法简化汉字,如“后”代“後”;两个繁体字共用一个简化字,如“臟、髒”合并用“脏”,这样共减少了100多个字。另外,有些形声字改换声旁,表音更准确,如“态(態)、战(戰)”等;有些字简化后部件更便于称说,如“灶”(竈)等。几十年来的实践证明,简化字有利于人民群众,特别有利于中小学语文教学和扫盲工作,受到了广大群众的欢迎。
(二)整理异体字
异体字是音同、义同而形体不同的字,如“柏(栢)、冰(氷)、耻(恥)、劫(刼刧刦)”等。异体字的产生,大致有以下几种原因:
①繁体简体同时存在。例如“貓”和“猫”、“僊”和“仙”等。
②古字今字同时使用。例如“采”和“採”、“志”和“誌”等。
③偏旁不稳定,有一定的可变性。例如“凉”和“涼”、“糖”和“餹”等。
④偏旁部位任意移动。例如“绵”和“緜”、“峰”和“峯”等。
⑤笔画增减或笔形变更。例如“冰”和“氷”等。
⑥应用不同的方法造同一个字。例如“膻”是形声字,而“羴”是会意字;“丫”是象形字,而“桠”是形声字等。
⑦原形声字作假借字用后,假借字增添了形旁。例如:“念”和“唸”、“赞”和“讚”等。
这类异体字较多,只会增加人们的负担。例如在阅读时,知道一个比较通用的“膻”还不够,还得额外再记住同音同义的“羶羴”。这在学习和应用中会浪费时间和精力,在印刷、打字等工作中会浪费物质财富。这类异体字必须整理。
1955年12月,文化部和文改会公布了《第一批异体字整理表》,这个表列出810组异体字,共1865个。根据从俗从简的原则,每组选定一种形体用作规范字,其余的1055个为异体字,一般不在书报杂志等出版物中出现。翻印古书或作姓氏用时,可以例外。
(三)规范印刷体字形
1965年,文化部和文改会公布了《印刷通用汉字字形表》,共收通用的印刷体字6196个;1988年3月,国家语委、新闻出版署发布了《现代汉语通用字表》,收字7000个。这两个字表明确规定了每个字的字形标准。例如,采用“者、直、普”等不用“![]() 、
、![]() 、
、![]() ”等。这样,印刷体字形统一了,印刷体和手写楷书也基本上一致了,精简了一些在印刷上有特殊写法的字,很有利于汉字的学习和使用。
”等。这样,印刷体字形统一了,印刷体和手写楷书也基本上一致了,精简了一些在印刷上有特殊写法的字,很有利于汉字的学习和使用。
(四)更改生僻地名用字
从1956年到1964年,全国有8个省和自治区的35个地区和县经国务院批准,更改了生僻的地名用字。例如,陕西的盩厔县、郃阳县改为周至县、合阳县,青海的亹源回族自治县改为门源回族自治县等,共精简生僻字30多个。
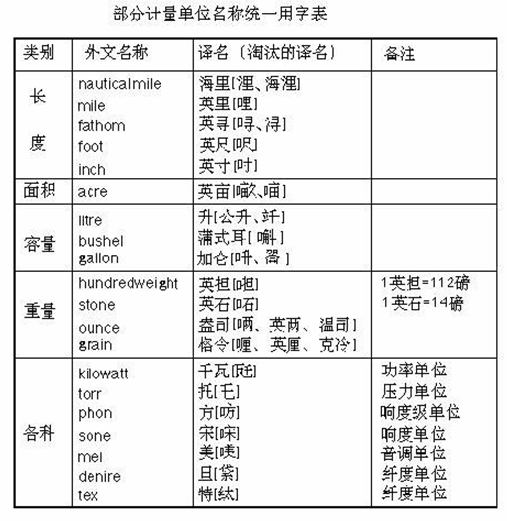
(五)统一计量单位名称用字
1977年7月20日,文改会和国家标准计量局发出《关于部分计量单位名称统一用字的通知》,要求“采用附表选定的译名,淘汰其他旧译名”。例如,废除表示长度的“浬、海浬”,改称海里;废除表示面积的“𠺖、![]() ”,改称英亩;废除表示容量的“呏、嗧”,改称加仑;废除表示重量的“𠵆、𠰴”,改称英担、英石等。这样,共精简旧译名字20多个。
”,改称英亩;废除表示容量的“呏、嗧”,改称加仑;废除表示重量的“𠵆、𠰴”,改称英担、英石等。这样,共精简旧译名字20多个。
(六)整理异读词
现行汉字的读音,有不确定的情况。例如过去“庇”读bì,又读pì;“殊”读shū,又读chū。普通话审音委员会于1957年、1959年、1962年先后发表了《普通话异读词审音表初稿》,并于1963年辑录成《普通话异读词三次审音总表初稿》(以下简称《初稿》)。1982年重建了普通话审音委员会,对《初稿》进行修订;1985年,国家语委、国家教委、广播电视部发布了《普通话异读词审音表》。这样,普通话异读词的读音就有了规范化的标准。例如“庇”只读bì,“殊”只读shū,其余的读音废除。国家语委、国家教委、广播电视部在《关于〈普通话异读词审音表〉的通知》中指出:“这次修订以符合普通话语音发展规律为原则,以便利广大群众学习普通话为着眼点,采取约定俗成、承认现实的态度。对《初稿》原订读音的改动,力求慎重。”
(七)研制《通用规范汉字表》
2001年4月,教育部、国家语委启动了《规范汉字表》的研制工作,历经十余年完成。2013年6月5日,国务院公布了《通用规范汉字表》,这个字表分为三级:一级字表为常用字表,收字3500个,主要满足基础教育和文化普及的基本用字需要。二级字表收字3000个,使用度仅次于一级字。三级字表收字1605个,是姓氏人名、地名、科学技术术语和中小学语文教材文言文用字中未进入一、二级字表的较为通用的字。全表共收入通用规范汉字8105个,既能满足出版印刷、辞书编纂和信息处理等方面的一般用字需要,也能满足信息化时代与大众生活密切相关的专门领域的用字需要。
《通用规范汉字表》对《现代汉语通用字表》有所调整,收入《现代汉语通用字表》中的通用规范汉字6962个,又增加了1143个《现代汉语通用字表》没有收入的通用规范汉字。《通用规范汉字表》是最新的通用字字集,具有替代《现代汉语通用字表》的功能。
《通用规范汉字表》没有收入《简化字总表》中“饦、㧏、䥺”等31个非通用简化字,新增加“闫、、”等226个《简化字总表》和《现代汉语通用字表》中没有的简化字,共收录2546个通用规范简化字,它是通用字范围内的简化字的规范。
《通用规范汉字表》对《第一批异体字整理表》也有所调整,确认此前几个文件对26个异体字的调整,又调整“皙、喆、淼、昇、邨”等45个异体字为规范字。其附件1《规范字与繁体字、异体字对照表》中规范字跟异体字的对照,有替代《第一批异体字整理表》的功能。
三、汉字的标准化
汉字标准化,要求对汉字进行四定,即定量、定形、定音、定序。《通用规范汉字表》是最新的现代汉语通用字字量、字形和字序规范。
(一)定量
定量,是指规定现代汉语用字的数量;以便于汉字的学习和运用,便于现代化建设中电子计算机控制的电讯传递、情报检索、指挥调度、生产管理以及打字印刷等的汉字处理。
现代通用汉字有多少个?概括起来说,大体在6000到9000之间。通用字的研究从20世纪50年代就开始了。1955年,文改会编印了《通用字表(初稿)》,收字5709个;修订后于1965年公布了《印刷通用汉字字形表》,收字6196个。这是通用汉字研究的初步成果。1981年,国家标准局发布《信息交换用汉字编码字符集·基本集》(GB2312—80),收字6763个。1988年,国家新闻出版署、国家语委发布《现代汉语通用字表》,收字7000个。2013年《通用规范汉字表》收字8105个,是最新的“现代汉语通用字表”。
现代汉语常用字有三四千个。在过去常用字研究的基础上,国家语委和国家教委于1988年发布了《现代汉语常用字表》,其中常用字2500个,次常用字1000个。对300万字语料的检测结果是:2500个常用字覆盖率达97.97%,1000个次常用字覆盖率达1.51%,3500个字合计覆盖率达99.48%。2013年《通用规范汉字表》的一级字表,是最新的“现代汉语常用字表”。
(二)定形
定形,是指规定现行汉字的标准字形。在新中国成立后的汉字整理过程中,先后公布了《第一批异体字整理表》、《简化字总表》、《印刷通用汉字字形表》、《现代汉语通用字表》、《通用规范汉字表》等,为汉字的定形工作打下了较好的基础。
为了适应定形的要求,今后对简化汉字笔画的工作,要采取审慎的态度。为了保持字形的稳定性,在一定时期内不应该对汉字进行笔画的简化。在将来需要对某些汉字的笔画进行简化时,要注意采用恰当的方式。
汉字定形的一个重要任务是进一步整理异体字。另外,《第一批异体字整理表》中对有些字的处理不太恰当,也应当加以调整。
(三)定音
定音,就是确定现行汉字的规范字音。要规范多音字的读音,减少异读,使汉字的读音明确,易学易用。在定音方面,我们已经做了许多工作,其中最重要的就是异读词的审音。1985年公布的《普通话异读词审音表》审订了839条异读字的读音。
《普通话异读词审音表》公布之后,有些审音引起了不同的意见。例如“荫”统读yìn,废除yīn的音义,但是地名用字如黑龙江嘉荫县、人名用字如杨荫榆中的“荫”一般读阴平。又如,“胜”统读shèng,但是《现代汉语词典》(2005版)等一般词典都还另外读shēng,指一种有机化合物“肽”。这些问题应当妥善解决。
现行汉字的定音工作还要继续进行。人名、地名的异读,要进一步审订。轻声词、儿化词在书面上表示不出来,口语里有一定的随意性,应该编写相应的词表。另外,一些多音多义字的读音也应该审订。例如,“称”在一般字典中有三个读音:(1)chēng(称呼、称一称),(2)chèn(相称),(3)chèng(同“秤”)。《通用规范汉字表》收“秤”,说明“秤”是通用汉字,因此应当废除“称”的chèng读音,只让“秤”来记录这个音义,“称”的读音就减少了。类似的多音多义字,应把定音和定量、定形结合起来考虑,采取最佳方法进行审订。
2011年10月国家语委启动了新中国成立以来第三次普通话审音工作,2016年6月公布了《〈普通话异读词审音表〉(修订稿)征求意见公告》,这个“修订稿”正式公布后,将成为汉字定音的一个新标准。
(四)定序
定序,就是确定现行汉字的规范字序。排列汉字便于查检汉字,所以又称检字法。工具书的编写、档案、资料索引的编排,印刷铅字的排列,计算机汉字字库的编制和汉字信息处理等,都要求汉字有定序。
汉字的排列方法有义序法、音序法和形序法三大类。
义序法是按照字义进行分类来排列字的顺序,过去的《尔雅》、《释名》等采用这种方法。按意义排序很难定出明确一致的标准,现在一般不采用了,而采用音序法和形序法。
音序法是按照字音排列汉字的顺序。古代的韵书采用的是音序法。《汉语词典》、《同音字典》、《第一批异体字整理表》,都是按注音字母的顺序排列的。1958年《汉语拼音方案》公布之后,《新华字典》、《现代汉语词典》的正文都按汉语拼音字母的顺序排列。由于同音汉字很多,不得不辅以形序法解决同音字的排列先后问题。音序法的主要优点是简明,便于查检。但是它有个致命的弱点,那就是不会念的字无法查检。用音序法编排的字书,一般还要附有部首或笔画的检字表,所以大型字书一般不采用音序法。
形序法是按照字形排列字的顺序,主要可分为笔画法、部首法和号码法三种。由于汉字字形各异,全由笔画组成,我们可以利用笔画数、笔顺、笔形等给所有汉字定序。
下面介绍几种常见的字序。
1.笔画序
笔画序根据笔画数和笔形的顺序编排汉字。有两条主要规则,第一条是“笔画数规则”,即按笔画数从少到多排列,第二条是“笔顺规则”,即同笔数的字按笔顺逐笔比较笔形定序,首笔笔形相同的,再按第二笔的笔形顺序排列,依此类推。
关于笔形的顺序,有不同的主张,1964年汉字查字法工作组推荐“札”字法(一丨丿丶乛),目前采用的也较多。但是同笔数、同笔形顺序的字,在不同的字表中顺序仍有分歧。国家语委会1999年发布、2000年实施的《GB1300.1字符集汉字字序(笔画序)规范》(以下简称《规范》)增加了三条规则:(1)“主附笔形规则”:主笔形先于附笔形,例如:子孑、干于、夕久;折点数少的先于折点数多的,例如:刀乃、么凡;折点数相同时,按折笔起笔的笔形顺序定序,例如:久么;折点数、起笔形都相同,依折笔后的笔形顺序定序,例如:丸及。(2)“笔画组合关系规则”:相离先于相接,相接先于相交,例如:八人、凡丸;另外有先短后长等定序法,例如:未末土士。(3)“结构方式规则”:左右结构先于上下结构,上下结构先于包围结构,字形比例小的先于字形比例大的,例如:胶曼、旮旭、口囗。上述规则,是在用前面的规则不能定序时才采用的。运用这种规则,《规范》中对通用字3画撇折点笔形的字作如下定序:夕久么勺凡丸及。这样,终于解决了笔画法定序的问题。
2.部首·笔画序
部首·笔画序先根据部首把汉字分部排序,再在每一部中根据笔画序编排汉字。以前的字(词)典部首多不相同。1983年《文字改革》第11期刊登了文改会和文化部出版局联合组织的汉字部首排检法工作组拟订的《统一汉字部首表》(征求意见稿),1998年《语文建设》第11期又刊登了该表标准研制组的修订稿,共201个部首。教育部、国家语委2009年1月12日发布、2009年5月1日实施的《汉字部首表》,其中主部首201个,如“门、刀、日”等;附属于主部首的附形部首100个,如“门”的繁体部首“門”、“刀”的变形部首“刂”、“日”的从属部首“曰”等。各主部首的序号为固定编号,附形部首的序号与主部首一致。《汉字部首表》明确规定:“使用本部首表时,一般应以主部首为主。”但是在特殊情况下可以变通:(1)某些辞书“可根据传统和实际需要,用繁体部首或变形部首、从属部首作为主部首”,如“貝(贝)、艸(艹)、玉(王)”等。(2)“某些辞书可同时采用主部首和收字较多的附形部首。”例如“车(車)”,“简、繁字都收的辞书可将简化字归入‘车’部,将繁体字归入‘車’部”。(3)“用于旧印刷字形的检索时,可将本表的部首转换为旧印刷字形,部首序号不变。”例如“49辶”转换为“49![]() ”。“新旧字形同时存在的字集中,旧字形可归入对应的新字形部首”,例如“黃”归入“黄”部等。
”。“新旧字形同时存在的字集中,旧字形可归入对应的新字形部首”,例如“黃”归入“黄”部等。
3.拼音·笔画序
拼音·笔画序是先根据汉语拼音把汉字分部排序,再在每一部中根据笔画序编排汉字。
拼音·笔画序首先是按汉字字音的汉语拼音书写形式给汉字排序。汉语拼音字母有26个,其中23个可作汉字拼音的首字母,因此可以根据字母表的顺序,把汉字分为23大部。《现代汉语词典》、《现代汉语规范词典》的“音节表”都分23大类。汉语不带声调的音节有400多个,《新华字典》的正文便按照不带声调的音节分415部。汉语中带声调的音节为1300个左右,《现代汉语词典》正文便按照带声调的音节分1335部,《现代汉语规范词典》正文按带声调的音节分为1310部。
拼音·笔画序的第二步是给音节书写形式相同的字按笔画序的五条规则排序。以前一些字典词典给同音字排序不尽一致,例如rèn音节字的排列:
《新华字典》(2005年版):刃仞纫韧轫牣认任饪妊纴衽葚
《现代汉语词典》(2005年版):刃认仞讱任纫韧轫牣饪妊纴衽葚
随着《GB13000.1字符集汉字字序(笔画序)规范》的实施,以上差异有可能消除。2004年版《现代汉语规范词典》,2005年版《现代汉语词典》对rèn音节字的排列是一致的。
4.字角号码序
字角号码序按字角确定的号码编排汉字。最通行的号码法是四角号码。它按字的四角笔形确定数码,其口诀是“横一垂二三点捺,叉四插五方块六,七角八八九是小,点下有横变零头。”即“1”横(一)、“2”竖(丨、丿)、“3”点捺(丶、㇏),“4”叉(十)、“5”插(扌、丰)、“6”方块(口),“7”角(月、阝)、“8”八(八、人)、“9”小(小、忄),点下加横(亠)变“0”头。四角的顺序是先取左上到右上,后取左下到右下。如,“船”的四角是丿𠃍𠂇口,号码是2746,“久”的四角是丿𠃍八,号码是2780。为了减少重码字,又规定增加附角号码,即右下角上方最贴近的笔形。例如:迹30303避30304。商务印书馆出版的字典、词典和其他工具书大都附有四角号码检字索引。《四角号码新词典》对早出的四角号码查字法做了一些改进。近年来提出不少改进方案,有的仍采用四角号码,有的则采用三角号码等。号码法还需要进一步改进。
总体来看,现在通行的音序法和形序法都有许多值得研究的问题,需要进一步标准化,做到每一个通用汉字都有一个固定的排列顺序。
四、汉字的信息处理
汉字信息处理,有广义、狭义两种不同的理解。广义的汉字信息处理即汉语信息处理,就是使用计算机对汉语的音、形、义等信息进行的处理,也就是通常所说的中文信息处理。狭义的汉字信息处理是指用计算机对汉字表示的信息进行的操作和加工,是中文信息处理的一个重要的组成部分。中文信息处理的首要问题就是汉字的信息处理,这是汉语的独特任务。
汉字信息处理系统主要包括输入、存储、加工和输出等模块。
(一)汉字信息输入
汉字输入是指利用汉字的形、音或相关信息等多种方式把汉字输送到计算机中去的过程。汉字输入方法有三种:汉字识别输入、语音识别输入和汉字键盘输入。
汉字键盘输入是目前汉字信息处理中最通行、最常用的汉字输入方法。汉字的键盘输入技术经历了三个发展阶段,即字处理阶段、词处理阶段和句子处理阶段目前正处于第三个阶段。运用键盘输入的关键技术是汉字编码问题。
汉字的编码方案先后提出了几百种,只有少数几种已经被用户接受并广泛使用。汉字编码的方法概括起来主要有字形编码法(形码,分为笔画式编码、字根代码类两种)、字音编码法(音码,拼音编码)和形音结合编码法(形音码或音形码)三类。
(二)汉字信息存储
汉字信息存储是把汉字属性信息(字量、字频、字序、字形、字音等)和其他有关信息存储在计算机内。通常主要指汉字字形的存储,它与汉字字形库(简称汉字库)设计有关。汉字字形库是建立在计算机存储媒体上的汉字的字模数据集合,它是汉字信息处理系统用来产生汉字字形和各种图形符号的基础部件,也是西文计算机和信息处理没有遇到的特殊情况,所以,汉字字形存储是汉字信息处理的一项关键技术。
(三)汉字信息加工
汉字信息的加工处理包括不同的要求,例如,在文稿的编辑操作中对文字、句子进行的增加、删除、修改等操作,对汉字串进行的分类、合并、排序、检索以及对齐等操作。通常都离不开一些软件,例如Microsoft Word、金山WPS等。
(四)汉字信息输出
把经过计算机加工处理后的汉字信息传输给人或其他设备,就是汉字信息输出。在汉字信息加工完毕之后,要把处理结果的代码信息转换成文字的形式输出,输出的方式主要包括显示输出和打印输出。
随着计算机的日益普及和网络的快速发展,汉语的信息处理面临新的挑战和机遇,内容也日益丰富。书报的自动编辑和排版、办公自动化、图书、情报的自动编目和检索、机器翻译、中文信息的检索和自动提取网络办公、机器自动问答等,都离不开汉字的信息处理。只有不断提高汉字信息处理的水平,才能改变我国信息化水平后进的现状,确立我国在中文信息处理领域的国际领先地位,在世界高新科技竞争中占据一席之地。
请同学们继续学习
