第二章 数据流图
当数据在软件系统中移动时,它将被一系列“变换”所修改。数据流图(DFD)是一种图形化技术,它描绘信息流和数据从输入移动到输出的过程中所经受的变换。在数据流图中没有任何具体的物理部件,它只是描绘数据在软件中流动和被处理的逻辑过程。数据流图是系统逻辑功能的图形表示,即使不是专业的计算机技术人员也容易理解它,因此是分析员与用户之间极好的通信工具。此外,设计数据流图时只需考虑系统必须完成的基本逻辑功能,完全不需要考虑怎样具体地实现这些功能,所以它也是今后进行软件设计的很好的出发点。
 知识点一:符号
知识点一:符号
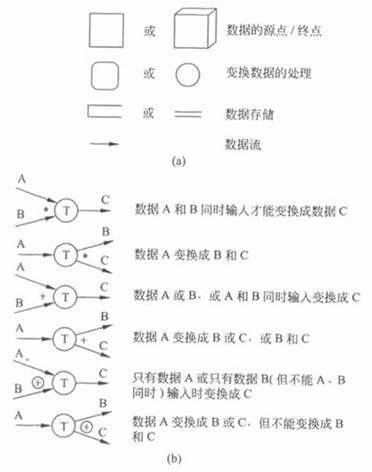
如图3.1(a)所示,数据流图有四种基本符号:正方形(或立方体)表示数据的源点或终点;圆角矩形(或圆形)代表变换数据的处理;开口矩形(或两条平行横线)代表数据存储;箭头表示数据流,即特定数据的流动方向。注意,数据流与程序流程图中用箭头表示的控制有本质不同,千万不要混淆。熟悉程序流程图的初学者在画数据流程图时,往往试图在数据流程图中表现分支条件或循环,殊不知这样将造成混乱,画不出正确的数据流图。在数据流图中应该描绘所有可能的数据流向,而不应该描绘出现某个数据流的条件。
处理并不一定是一个程序。一个处理框可以代表一系列程序、单个程序或者程序的一个模块;它甚至可以代表用穿孔机穿孔或目视检查数据正确性等人工处理过程。一个数据存储也并不等同于一个文件,它可以表示一个文件、文件的一部分、数据库的元素或记录的一部分等;数据可以存储在磁盘、磁带、磁鼓、主存、微缩胶片、穿孔卡片及其他任何介质上(包括人脑)。
数据存储和数据流都是数据,仅仅所处的状态不同。数据存储是处于静止状态的数据,数据流是处于运动中的数据。
通常在数据流图中忽略出错处理,也不包括诸如打开或关闭文件之类的内务处理。数据流图的基本要点是描绘“做什么”而不考虑“怎样做”。
有时数据的源点和终点相同,如果只用一个符号代表数据的源点和终点,则至少将有两个箭头和这个符号相连(一个进一个出),可能其中一条箭头线相当长,这将降低数据流图的清晰度。另一种表示方法是再重复画一个同样的符号(正方形或立方体)表示数据的终点。有时数据存储也需要重复,以增加数据流图的清晰程度。为了避免可能引起的误解,如果代表同一个事物的同样符号在图中出现在n个地方,则在这个符号的一个角上画(n-1)条短斜线做标记。
除了上述4种基本符号之外,有时也使用几种附加符号。星号(*)表示数据流之问是“与”关系(同时存在);加号(+)表示“或”关系;⊕号表示只能从中选一个(互斥的关系)。图2.4(b)给出了这些附加符号的含义。
知识点二:例子
下面通过一个简单例子具体说明怎样画数据流图。
假设一家工厂的采购部每天需要一张定货报表,报表按零件编号排序,表中列出所有需要再次定货的零件。对于每个需要再次定货的零件应该列出下述数据:零件编号,零件名称,定货数量,目前价格,主要供应者,次要供应者。零件入库或出库称为事务,通过放在仓库中的CRT终端把事务报告给定货系统。当某种零件的库存数量少于库存量临界值时就应该再次定货。
怎样画出上述定货系统的数据流图呢?数据流图有4种成分:源点或终点,处理,数据存储和数据流。因此,第一步可以从问题描述中提取数据流图的4种成分:首先考虑数据的源点和终点,从上面对系统的描述可以知道“采购部每天需要一张定货报表”,“通过放在仓库中的CRT终端把事务报告给定货系统”,所以采购员是数据终点,而仓库管理员是数据源点。接下来考虑处理,再一次阅读问题描述,“采购部需要报表”,显然他们还没有这种报表,因此必须有一个关于产生报表的处理。事务的后果是改变零件库存量,然而任何改变数据的操作都是处理,因此对事务进行的加工是另一个处理。注意,在问题描述中并没有明显地提到需要对事务进行处理。但是通过分析可以看出这种需要。最后,考虑数据流和数据存储:系统把定货报表送给采购部。因此定货报表是一个数据流;事务需要从仓库送到系统中,显然事务是另一个数据流。产生报表和处理事务这两个处理在时间上明显不匹配——每当有一个事务发生时立即处理它,然而每天只产生一次定货报表。因此,用来产生定货报表的数据必须存放一段时间,也就是应该有一个数据存储。
注意,并不是所有数据存储和数据流都能直接从问题描述中提取出来。例如,“当某种零件的库存数量少于库存最临界值时就应该再次定货”,这个事实意味着必须在某个地方有零件库存最和库存最临界值这样的数据。因为这些数据元素的存在时间看来应该比单个事务的存在时间长,所以认为有一个数据存储保存库存清单数据是合理的。
表3.1总结了上面分析的结果,其中加星号标记的是在问题描述中隐含的成分。
表3.1 组成数据流图的元素可以从描述问题的信息中提取
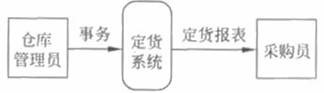
一旦把数据流图的4种成分都分离出来以后,就可以着手画数据流图了。但是,怎样开始画呢?注意,数据流图是系统的逻辑模型,然而任何计算机系统实质上都是信息处理系统,也就是说计算机系统本质上都是把输入数据变换成输出数据。因此,任何系统的基本模型都由若干个数据源点/终点以及一个处理组成,这个处理就代表了对数据加工变换的基本功能。对于上述的额定或系统可以画出图3.5这样的基本系统模型。
从基本系统模型这样非常高的层次开始画数据流图是一个好办法。在这个高层次的数据流图上是否列出了所有给定的数据源点/终点是一目了然的,因此它是很有价值的通信工具。
然而,图3.5毕竟太抽象了,从这张图上对定货系统所能了解到的信息非常有限。下一步应该把基本系统模型细化,描绘系统的主要功能。从表3.1可知,“产生报表”和“处理事务”是系统必须完成的两个主要功能,它们将代替图3.5中的“定货系统”(图3.6)。此外,细化后的数据流图中还增加了两个数据存储:处理事务需要“库存消单”数据;产生报表和处理事务在不同时间,因此需要存储“定货信息”。除了表3.1中列出的两个数据流之外还有另外两个数据流,它们与数据存储相同。这是因为从一个数据存储中取出来的或放进去的数据通常和原来存储的数据相同,也就是说,数据存储和数据流只不过是同样数据的两种不同形式。
在图2.6中给处理和数据存储都加了编号,这样做的目的是便于引用和追踪。
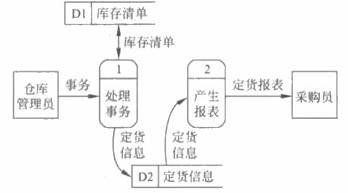
接下来应该对功能级数据流图中描绘的系统主要功能进一步细化。考虑通过系统的逻辑数据流:当发生一个事务时必须首先接收它;随后按照事务的内容修改库存清单;最后如果更新后的库存量少于库存量临界值时,则应该再次定货,也就是需要处理订货信息。因此,把“处理事务”这个功能分解为下述3个步骤,这在逻辑上是合理的:“接收事务”、“更新库存清单”和“处理订货”。
为什么不进一步分解“产生报表”这个功能呢?定货报表中需要的数据在存储的定货信息中全都有,产生报表只不过是按一定顺序排列这些信息,再按一定格式打印出来。然而这些考虑纯属具体实现的细节,不应该在数据流图中表现。同样道理,对“接收事务”或“更新库存清单”等功能也没有必要进一步细化。总之,当进一步分解将涉及如何具体地实现一个功能时就不应该再分解了。
当对数据流图分层细化时必须保持信息连续性,也就是说,当把一个处理分解为一系列处理时,分解前和分解后的输入输出数据流必须相同。例如,图3.5和图3.6的输入输出数据流都是“事务”和“定货报表”;图3.6中“处理事务”这个处理框的输入输出数据流是“事务”、“库存清单”和“定货信息”,分解成“接收事务”、“更新库存清单”和“处理定货”3个处理之后(图3.7),它们的输入输出数据流仍然是“事务”、“库存清单”和“定货信息”。
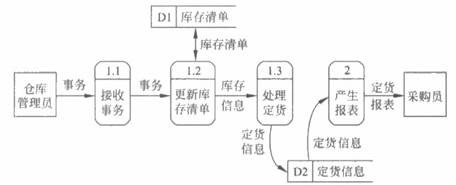
此外还应该注意在图2.7中对处理进行编号的方法。处理1.1,1.2和1.3是更高层次的数据流图中处理1的组成元素。如果处理2被进一步分解,它的组成元素的编号将是2.1,2.2,……;如果把处理1.1被进一步分解,则将得到编号为1.1.1,1.1.2,……的处理。
知识点三:命名
数据流图中每个成分的命名是否恰当,直接影响数据流图的可理解性。因此,给这些成分起名字时应该仔细推敲。下面讲述在命名时应注意的问题:
1.为数据流(或数据存储)命名
(1)名字应代表整个数据流(或数据存储)的内容,而不是仅仅反映它的某些成分。 (2)不要使用空洞的、缺乏具体含义的名字(如“数据”、“信息”、“输入”之类)。 (3)如果在为某个数据流(或数据存储)起名字时遇到了困难,则很可能是因为对数据流图分解不恰造成的,应该试试重新分解,看是否能克服这个困难
2.为处理命名
(1)通常先为数据流命名,然后再为与之相关联的处理命名。这样命名比较容易,而且体现了人类习惯的“由表及里”的思考过程。 (2)名字应该反映整个处理的功能,而不是它的一部分功能。 (3)名字最好由一个具体的及物动词加上一个具体的宾语组成。应该尽量避免使用“加工”、“处理”等空洞笼统的动词作名字。 (4)通常名字中仅包括一个动词,如果必须用两个动词才能描述整个处理的功能,则把这个处理再分解成两个处理可能更恰当些。 (5)如果在为某个处理命名时遇到困难,则很可能是发现了分解不当的迹象,应考虑重新分解。
数据源点/终点并不需要在开发目标系统的过程中设计和实现,它并不属于数据流图的核心内容,只不过是目标系统的外围环境部分(可能是人员、计算机外部设备或传感器装置)。通常,为数据源点/终点命名时采用它们在问题域中习惯使用的名字(如“采购员”、“仓库管理员”等)。
知识点四:用途
画数据流图的基本目的是利用它作为交流信息的工具。分析员把他对现有系统的认识或对目标系统的设想用数据流图描绘出来,供有关人员审查确认。由于在数据流图中通常仅仅使用4种基本符号,而且不包含任何有关物理实现的细节,因此,绝大多数用户都可以理解和评价它。
从数据流图的基本目标出发,可以考虑在一张数据流图中包含多少个元素合适的问题。一些调查研究表明,如果一张数据流图中包含的处理多于5-9个,人们就难于领会它的含义了。因此数据流图应该分层,并且在把功能级数据流图细化后得到的处理超过9个时,应该采用画分图的办法,也就是把每个主要功能都细化为一张数据流分图,而原有的功能级数据流图用来描绘系统的整体逻辑概貌。
数据流图的另一个主要用途是作为分析和设计的工具。分析员在研究现有的系统时常用系统流程图表达他对这个系统的认识,这种描绘方法形象具体,比较容易验证它的正确性;但是,开发工程的目标往往不是完全复制现有的系统,而是创造一个能够完成相同的或类似的功能的新系统。用系统流程图描绘一个系统时,系统的功能和实现每个功能的具体方案是混在一起的。因此,分析员希望以另一种方式进一步总结现有的系统,这种方式应该着重描绘系统所完成的功能而不是系统的物理实现方案。数据流图是实现这个目标的极好手段。
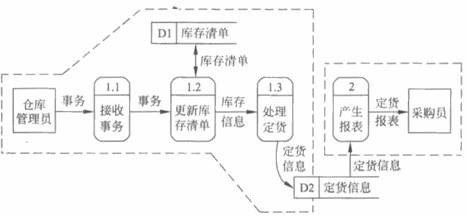
当用数据流图辅助物理系统的设计时,以图中不同处理的定时要求为指南,能够在数据流图上画出许多组自动化边界,每组自动化边界可能意味着一个不同的物理系统,因此可以根据系统的逻辑模型考虑系统的物理实现。例如,考虑图3.7,事务随时可能发生,因此处理1.1(“接收事务”)必须是联机的;采购员每天需要一次定货报表,因此处理2(“产生报表”)应该以批量方式进行。问题描述并没有对其他处理施加限制,例如,可以联机地接收事务并放入队列中,然而更新库存清单、处理定货和产生报表以批量方式进行(图3.8)。当然,这种方案需要增加一个数据存储以存放事务数据。

改变自动化边界,把处理1.1,1.2和1.3放在同一边界内(图3.9),这个系统将联机地接收事务、更新库存清单和处理订货及输出订货信息;然而处理2将以批量方式产生订货报表。还能设想出建立自动化边界的其他方案吗?如果把处理1.1和处理1.2放在一个自动化边界内,把处理1.3和处理2放在另一个边界内,意味着什么样的物理系统呢?
数据流图对更详细的设计步骤也有帮助,本课第4章将讲述从数据流图出发映射出软件结构的方法——面向数据流的设计方法。
请同学们继续学习
